

Photo by Markus Spiske on Unsplash
Demystifying x86 Assembly: An Introduction and How-To
this takes time to learn - don't be discouraged


I've been slowly learning assembly over the years by being exposed to it in my role as a Threat Analyst, but I would still consider myself to be a beginner. Lately, I've been taking action and learning more about it so that I can feel comfortable in a debugger and disassembler.
How I Started Learning
We should start from the beginning - I don't have a background in Computer Science. I went to college for Network Engineering because I thought switches, routers, and networking were really interesting. After graduating and starting on my Cisco certifications, I realized that it wasn't the career path for me. I have nightmares of Packet Tracer to this day. I worked as a System Admin for years, and then made the switch into cyber.
Naturally, working as a System Admin and having a background in networking does set me up with a solid and required foundation but it does nothing for understanding assembly, memory management, the Windows API, etc - skills that you often need when it comes to malware analysis and RE.
My advice here would be: don't be discouraged. If you had a degree/background in Computer Science, you would have the upper hand when it comes to learning assembly but on the flip side you'd have a lack of understanding in relation to networking, sysadmin, and perhaps other skillsets that are nice to have for malware analysis. We all have our struggles.
Optional Reading (but really recommend)
The following books are helpful:
Code: The Hidden Language of Computer Hardware and Software - This book does an excellent job of explaining how computers work and will familiarize you with number systems, gates, switches, etc.
Practical Malware Analysis: A Hands-On Guide to Dissecting Malicious Software - An excellent resource for malware analysis!
That's it. Let's keep it approachable and doable instead of daunting. You may be wondering why I don't have an x86 assembly book listed here. When it comes to learning something dry or complicated like this, I personally don't learn from reading alone. I need to do in order to learn, and instead, I would recommend this video series: Learning x86 with NASM
If you must have a book, then "Assembly Language Step by Step" is supposedly good, as well as "Assembly Language for x86 Processors" by Kip Irvine. I would advise you use them to supplement your learning and not as your only point of learning. Unless you like to read this sort of stuff, then by all means go for it. I will be honest, I’ve read neither because as I’ve explained I don’t learn that way. I do plan to read them now, and I think I’ll pick up a lot more than if I read them prior to having more understanding of the subject. Up to you!
x86 History (a quick overview)
There was once a time when this was all pioneered and it was much more difficult than the layers of abstraction we work with today. We should consider ourselves lucky. Side note: Are you also shocked when you stumble across man pages that are dated from the 80s and early 90s? (seriously, how?)
Anyway, assembly is a low level programming/machine language which can directly communicate with the processor. When we think of a language like Python, we are very abstracted from this low level, meaning there are a lot of layers between our Python code and what is happening at the processor level. With assembly, we are much closer - there is a lot less abstraction. This is what makes it difficult.
Keep in mind that assembly is specific to the hardware architecture, and in this blog we're talking about Intel x86, not ARM, MIPS, or anything else. Note: AMD is x86/x86-64 too.
The reason why it's called "x86" is because back in 1978 when Intel came out with their 16-bit 8086 microprocessor, there were successors named similarly: 80186, 80286, 80386, 80486, and it became easier to just write x86. You may also run into different syntax when it comes to x86, whether it be Intel or AT&T syntax. We'll be focusing on Intel.
Intel vs AT&T
------ ------
mov eax, 0xb mov $0xb,%eax
Registers
Grab a coffee! x86 is a 32-bit processor architecture, meaning it refers to any 32-bit processor that is compatible with the x86 instruction set. This also means that the registers are 32-bits in size (4 bytes). 00000000 00000000 00000000 00000000

You may have seen registers before like eax, ebx, ecx, edx, and so on. Processor registers are the main "tool" used to write programs in assembly, think of them as variables since they are used to store and manipulate data. There are 8 general purpose registers in x86:
| Name | Description |
| EAX | Accumulator, automatically used by multiplication and division |
| EBX | General purpose |
| ECX | Loop counter used by the CPU |
| EDX | General purpose |
| ESI | General purpose. High speed memory transfer |
| EDI | General purpose. High speed memory transfer |
| EBP | Base pointer |
| ESP | Stack pointer |
Note: There are also 64 bit registers which are denoted with an "r", such as rax, rbx, rcx, rdx. That's not the focus of this blog since we want to start off easier with 32 bit instead of 64, but keep in mind if you see such registers, it just denotes a 64-bit architecture.
Special Purpose Registers
EIP: The instruction pointer. Holds the memory address of the next instruction to be executed. Helps keep track of the current execution point in a program, constantly changing
EFLAGS: This register holds the state of the processor which can contain various status flags:
| Acronym | Meaning |
| CF | Carry Flag |
| OF | Overflow Flag |
| SF | Sign Flag |
| ZF | Zero Flag |
| AC | Auxiliary Carry (or AF) |
| PF | Parity Flag |
High Bits and Low Bits of Registers
32-bit registers can be split in order to utilize the high or low bits of the register. For example:
EAX - 32 bits
AX - 16 bits
AH - 8 bits
AL - 8 bits
In this case, AH means "high bits" and AL means "low bits" of the AX register. The AX register is the lower 16 bits of the EAX register. In fact, EAX just means Extended AX. This same operation can be applied to other general purpose registers as well.
AX,BX, CX, DX and subsequently AH, AL, BH, BL, CH, CL, DH, DL that this refers to splitting a register and using certain bits of it instead of the entire 32 bit register.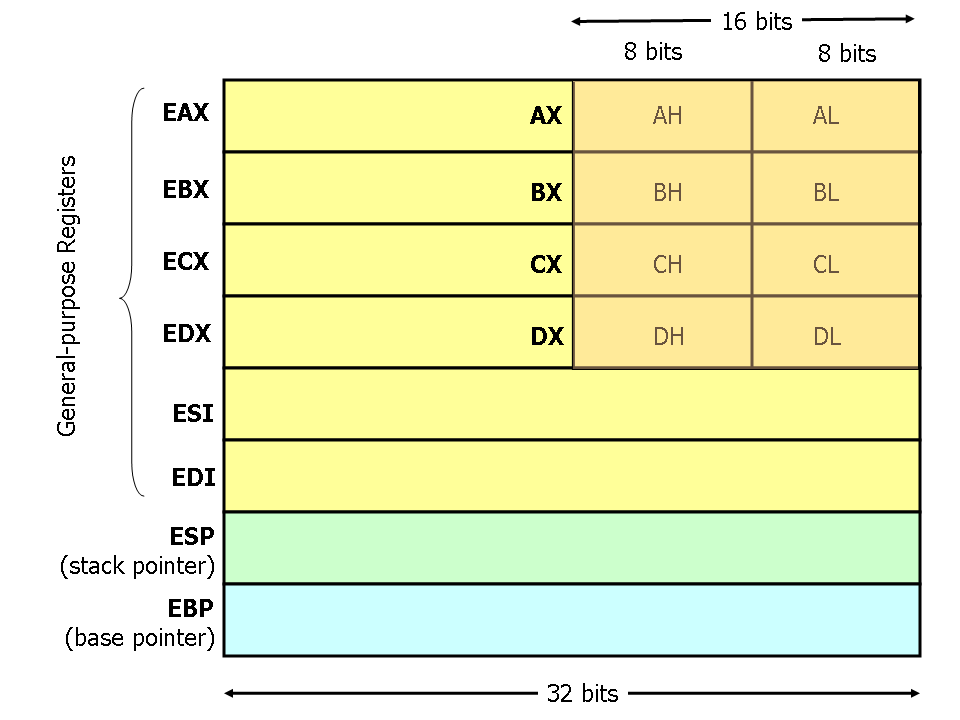
Common x86 Instructions (push, pop, mov, etc)
These are the instructions that the language uses in order to determine what to do with data. The instructions will handle data movement, arithmetic/logic/math, and control flow of the program. Every single time you look at a binary in a disassembler or debugger, you will be reading x86 instructions.
There are a lot of instructions in the x86 instruction set, but there are only a handful that you will typically run into. In fact, according to these statistics the mov instruction accounts for 35% of all instructions followed by push (10%) and call (6%)!
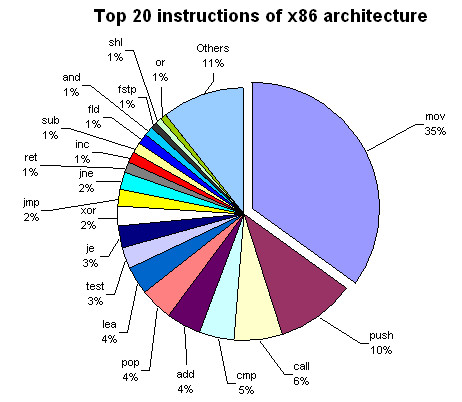
Data Movement:
Logic and Arithmetic:
Control Flow:
Important Concepts
Assuming you already understand number systems such as binary, hexadecimal, and decimal (of course you know this!), then there are a couple more key concepts that I personally find extremely helpful in understanding the why of certain things. If you need a refresher on binary, hexadecimal, and the different ways we can represent data, I advise you take some time to review that.
Key Concept: Endianness
Endianness refers to the order in which computer memory stores a sequence of bytes.
There are two types of endianness you'll run into, either big-endian (BE) or little-endian (LE).
Little Endian (LE)
Intel is based on Little Endian. This means that data is stored in RAM "little end" first. The LSB (least significant bit, aka right-most) of a word (data type) or larger is stored in the lowest address.
Big Endian (BE)
Stored in RAM "big end" first. The MSB (most significant bit, aka left-most) of a word or larger is stored in the lowest address. ARM is bi-endian (confusing, yes...not our problem here.)

Here's another example, but I edited the picture with the arrow showing the direction the address would grow, as well as fictitious memory addresses to get the point across.

To wrap this up without getting too in depth, I can show this in a debugger. Assume I take the assembly below and toss it into a debugger to step through the execution:
section .data ; example assembly storing SNOW in eax register
char DB 'SNOW',0
section .text
global _start
_start:
MOV eax,[char]
INT 80h

Now, in the debugger (gdb), what you'll see is that I've set a breakpoint on _start, executed the program, and stepped through execution until the interrupt (80h). Then, I display the contents of the memory address 0x804a000. Do you see 0x574f4e53? That is the hexadecimal representation of "WONS", which is our string in little-endian AKA little-end first. To further visualize, imagine the following, once again using fictitious memory addresses as a means of example:
'W' 'O' 'N' 'S'
0x1 0x2 0x3 0x4
Take some time to read up on this if you need to, I confused myself several times just writing this. Knowing the concept or the idea of the concept is enough for most people to notice when things stand out during analysis. Otherwise, you'd be scratching you're head at the order of bytes in memory.
Memory (Stack, Heap, etc)
Ah, the stack. I’ll be honest, of all the confusing areas of knowledge required to understand assembly, this confused me the most… especially not having a computer science background. How often does one think of memory management if they are not a programmer?
I was primarily confused because depending on who you talk to, they will explain it a different way than the last person…and I’ll probably explain it different than them. The way I finally started to understand what was going on was by watching the stack in x86dbg while dissecting basic C programs I wrote.
The stack is a region of memory that works like a stack of plates. The stack is fast and is a fixed size. Data is stored and retrieved in a Last In First Out (LIFO) order, and grows downward (high to low addresses). Primarily used for:
Local variables
Function parameters
Return addresses
Short-term data storage
Automatically cleaned up
The heap is a larger region of memory used for dynamic allocation. The heap is slower, is flexible in size, and grows upward (low to high addresses). Data can be stored and retrieved in any order, and is primarily used for:
Dynamic memory allocation
Large data structures
Long-term data storage
Data that needs to persist beyond function calls
Manually allocated and freed
We’re keeping this vague as it’s very easy to dive down a rabbit hole here and that’s not the point of this post. Here are some references though:
Finally: Dissecting a Hello World Program
Let’s create a classic “Hello World” program in C, and just for additional flair we’ll add a basic arithmetic function too. The program makes no sense from a functional standpoint, but it will show how we store data in registers, call functions, set up and clean the stack, etc.
Here is our basic C program. We’re defining a function called calculateTotal which takes 2 parameters, then adds them together. Then, we are calling the function with the values of 5 and 10, printing “Hello World”, and printing the result of the integer addition, which should be 15.
#include <stdio.h>
int calculateTotal(int a, int b) {
return a + b;
}
int main() {
int total = calculateTotal(5, 10);
printf("Hello World!\n");
printf("The result is: %d\n", total);
}
Let’s take a look at how this looks in our analysis VM. I think you’d be surprised to see the size of the file and the amount of imports, strings, and other indicators given what the program actually does. This is due to the compiler, runtime, and various variables during compilation, but this is a perfect example of why we need to understand how to reverse binaries at an assembly level.
On paper, this binary could look malicious. It’s 107kb in size, is novel in our environment, and if you look at the imported functions, it apparently has capabilities to write data to files, has anti-debug capability, and what can be seen as memory manipulation imports as well. Some may even write it off as malicious after a quick peek. This could of course lead to the improper training of machine learning models by classifying certain clean software as malicious, affect automated systems, lead an analyst down a rabbit hole etc.

Let’s toss it in IDA, where we can actually see what the program’s intent is. As we know, it’s to add two values and print “Hello World!” Note, this is not a blog on how to use IDA, and I’d be the worst teacher for that as I’m still learning all the tricks and secrets too.

Here is the main function. Let’s focus on the address range 0x401010 to 0x401046.
- The stack is set up between
0x401011and0x401013, also known as the “function prologue”:
push ebp <- push ebp onto the stack
mov ebp, esp <- move the stack pointer (esp) into ebp so we have a stable reference for the current stack frame
push ecx <- push ecx onto the stack
- At
0x401014and0x401016, both of our arguments which we are feeding to the function are now pushed onto the stack as hexadecimal “A” (10), and 5. You can convert “0Ah” into decimal by clicking it and hitting “h” in IDA.
push OAh <- push 10 (hex A) onto the stack
push 5 <- push 5 onto the stack
Now, we call the
calculateTotalfunction from our source code, which is represented as “call sub_401000” in IDA, at0x401018. We can rename that tocalculateTotal. Double clicking on “sub_401000”, nowcalculateTotal, takes us here, where the arithmetic happens:
In this function, we add the two values together as we expect. Since this is a new function call, the stack frame must be set up again. (function prologue). Then, at
0x401003and0x401006, the addition is completed.
mov eax, [ebp+arg_0] <- move the value stored at ebp+arg_0 into eax
add eax, [ebp+arg_4] < - add the value stored at ebp+arg_4 to eax
5 will be added to 10, and the hexadecimal value "0000000F" (15 decimal) will be
stored in the eax register.
[ebp+arg_0] in IDA mean that a memory address is being referenced. In IDA, you can see that “arg_0” is equal to 8, this is just IDA trying to be helpful. If you were to toss this into x86dbg, you can right click this and follow the selected memory address in the debugger. So it would look like [ebp+8]. Imagine that the value of the address in ebp is 00EFFB68 and you added 8 to it. That would be 00EEB70, and in that memory address would reside the value “5”. (one of our function arguments)We’re now returning the main function. In the
calculateTotalfunction, at0x401009wepop ebp, and then return. When wepop ebp, we restore the previously saved value for ebp by popping it off the stack. Afterwards, the next value on the stack will be the saved return address to the previous function.That address is saved by the
callinstruction when we first entered thiscalculateTotalfunction, and it performs two operations:Pushes the return address onto the stack
Jumps to the call target
Likewise, the retn instruction performs two operations:
Pop the return address off the stack
Jump to the return address
…That’s it for the calculateTotal function! Now let’s take a look at the printing:

Starting at
0x40101D, we are back in the main function. 8 is being added to esp in order to clean up the stack. In cdecl (the calling convention of C on x86_32 machines on Windows), the caller cleans up the stack. An int is 4 bytes and both parameters pushed totaled 8 bytes. That’s why 8 is being added to esp to “clean up the stack”. Calling conventions can change depending on the language, operating system, or if a developer calls for the binary to use a different calling convention.At
0x401023we push the string “Hello World!” onto the stack, and then at0x401028we call the print function. If we wanted to, we could renamesub_401090toprintf.
add esp, 8 <- clean up the stack
mov [ebp+var_4], eax <- move value of eax into [ebp+var_4], the value is 0000000F (15)
push offset aHelloWorld <- push pointer to Hello World onto stack
Next, the same thing with the calling convention occurs here at
0x40102Dwhere 4 is added to esp to clean up the stack.You may be thinking, “Hello World!” is more than 4 bytes long, so why are we only adding 4 to esp? It’s because we are referencing a pointer to the data section, and the size of the pointer is 4 bytes. So we may be referencing a memory address such as
0035B000for example that can contain the following:MEM ADDRESS | VALUE | | STRING 0035B000 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 0A 00 00 00 Hello World!....
When we add 4 back to esp in the previous step, we are now reunited with our value of “0000000F” or “15”, which is the sum of the
calculateTotalfunction. Can you kind of see how we bounce around in the program, and how esp is keeping us on track?Now, at
0x401030the value stored at[ebp+var_4](which is[ebp-4]) is moved into eax. Again, this is due to IDA trying to be helpful. The value stored at[ebp-4]is…. 15 (our sum). Then, eax is pushed onto the stack.We’re now ready to execute this part of our source code:
printf("The result is: %d\n", total);. Since eax is now pushed onto the stack, we can push a pointer to the string “The result is…” onto the stack as well, and then call the print function. (0x401034and0x401039). The program would then run and give us the output we expect:Hello World! The result is: 15And FINALLY between
0x401041-0x401046, we’re in the function epilogue. We clean up the stack again, this time we add 8 because there are two parameters, zero out eax via xor to set the return value to 0, pop ebp, and return control back to the C runtime environment.
I hope this was helpful! I know that there are lots of confusing bits. If there are any mistakes, please let me know. For further learning I heavily recommend creating basic binaries, stepping through the execution in a debugger and matching it 1:1 to what you’re looking at and analyzing in IDA (or Ghidra, BinaryNinja, etc). Even if it’s for simple binaries like this, it really helps piece it together. At least it did for me. Good luck and happy hunting!